
Custom Designed for Real-Time Consumer Applications
Quick Overview | TL;DR
As part of the Lagrange Point upgrade, Nibiru has fundamentally modified its Layer-1 architecture to deliver superior performance, enhanced developer flexibility, and robust, long-term security. This overhaul encompasses the introduction of NibiruBFT, a next-generation consensus mechanism, alongside a redesigned execution layer and native multi-VM support. Collectively, these enhancements enable Nibiru to handle high-throughput workloads across varied execution environments without compromising decentralization.
1 | Why Lagrange Point Matters
As Web3 adoption accelerates, a selection of networks have been struggling with expensive fees and delayed execution, undermining the user experience and increasing friction. Meanwhile, the increasing number of available virtual machines (VMs) complicates the development of knowledge transfer between chains, forcing developers to learn multiple execution environments and programming languages – a significant drain on time and resources.
Nibiru presents itself as a high-throughput Layer-1 blockchain designed to serve both developers and end users. Its core technology includes an EVM-compatible execution engine, parallel transaction processing, and a pioneering Multi VM framework that runs
Ethereum and WebAssembly smart contracts side by side. With sub-two-second finality and exceptionally low gas fees, the network promises a fast, cost-effective foundation for next-generation decentralized applications.
Lagrange Point, the chain’s flagship upcoming upgrade, pushes that advantage further by tackling three unsolved industry-wide challenges: scaling without centralization, bridging VM fragmentation, and future-proofing cryptography.
Lagrange combines clustered BFT consensus, BLS signature aggregation, and an adaptive multi-lane execution engine. The result is Solana-class throughput—tens of thousands of TPS—while retaining hundreds of independent validators and full Byzantine-fault tolerance. Transaction confirmation drops toward the one-second mark even under heavy load.
At the same time, Nibiru’s Multi VM architecture lets EVM and Wasm contracts run on the same state today and adds native Move VM and Solana VM next; for teams building with Move, comprehensive Move audits help harden contracts before production. Developers keep familiar tooling; assets and calls can move across VMs inside a single block, eliminating costly bridges and siloed liquidity.
Finally, Lagrange Point delivers lattice-based ML-DSA signatures aligned with NIST’s post-quantum standards, hardening Nibiru as a settlement layer designed to outlast Moore’s Law. Beyond cryptographic future-proofing, this upgrade sets the stage for a three-phase growth trajectory:
- Short-term: Own the “performance + EVM” niche (competing with Sei v2, Monad, MegaETH) by hitting industry-leading throughput benchmarks.
- Medium-term: Prove clustered BFT and adaptive execution at scale by onboarding a flagship perps DEX or RWA protocol, showcasing priority-lane edge.
- Long-term: Secure liquidity gravity. Cross-VM composability wins only if bridging UX and incentives rival Base’s Coinbase integration or Solana’s brand strength.
Nibiru’s “single-state convergence” — EVM familiarity plus Solana-style parallelism and Aptos-grade latency—directly tackles oracle lag, VM silos, and centralization risks. If benchmarks validate the design, Nibiru will stand alongside Aptos, Sui, and Solana when evaluated from a performance lens.
2 | Architecture-at-a-Glance
Nibiru Lagrange Point centers around two core systems:
- NibiruBFT: An evolution of the CometBFT consensus engine that reduces communication and signature overhead through validator clustering and BLS aggregation, while integrating modern and robust networking with QUIC and block/mempool laning, respectively.
- Nibiru Adaptive Execution: A contention-aware execution engine that dynamically reorders transactions for maximal throughput and parallelizability.
These two systems are complemented by Multi VM, a modular execution layer that allows EVM and Wasm contracts to co-exist natively on the same chain, with plans for additional VM support.
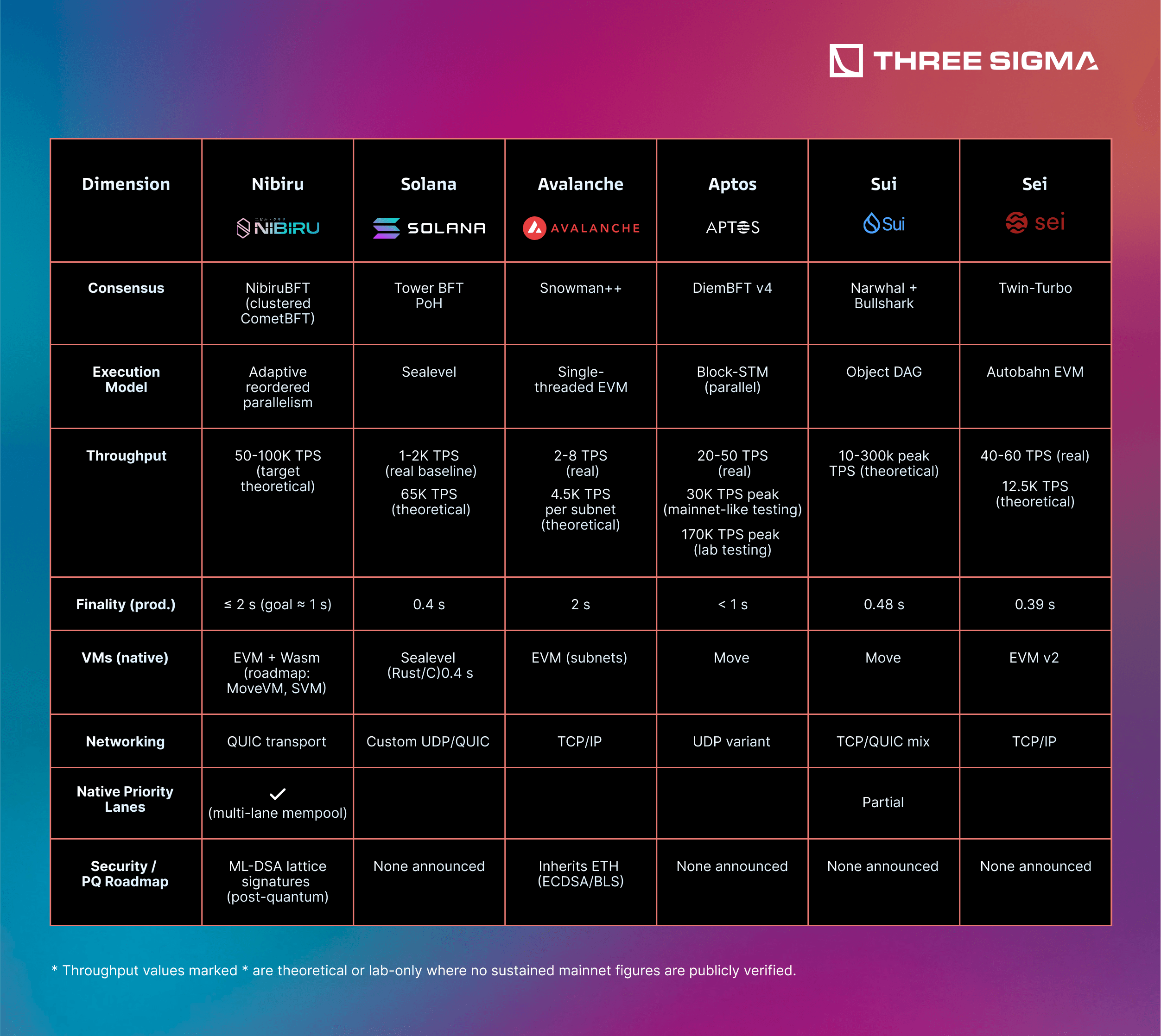
3 | Peer Comparison Highlights
The comparison below distills how each “performance-maxi” chain tackles speed, execution, and security. One clear takeaway: Nibiru is the only network that combines Solana-class parallel throughput targets, a multi-VM roadmap (EVM + Wasm live, Move/SVM next), native priority lanes, QUIC networking, and an explicit post-quantum signature plan—while still aiming to keep hundreds of independent validators.
In other words, it seeks the throughput of Solana and Aptos without their hardware centralization trade-offs, plus cross-VM composability and long-term cryptographic resilience that its peers have yet to match.
4 | Consensus Layer: NibiruBFT
4.1 | NibiruBFT – Enhanced Consensus Protocol
NibiruBFT is Nibiru’s CometBFT-modified Byzantine Fault Tolerant consensus mechanism, forming the backbone of the Lagrange Point roadmap. It builds upon the Cosmos/Tendermint (CometBFT) instant-finality model with several optimizations for scalability and speed. The design retains <2 second block times and immediate finality but reduces overhead through novel techniques.
Notably, NibiruBFT integrates improvements like signature aggregation and hierarchical consensus (detailed below) to address bottlenecks in standard BFT. By streamlining voting and block propagation, NibiruBFT aims to increase throughput and lower consensus latency beyond traditional Tendermint-based chains.
For example, baseline Tendermint can handle on the order of a few hundred TPS with ~1–2s finality in optimal settings; NibiruBFT targets significantly higher performance. In effect, NibiruBFT serves as the umbrella framework under which several innovations (BLS, clustering, QUIC, etc.) operate to collectively improve consensus throughput and scalability
Comparable Benchmark: Modern BFT consensus implementations like Aptos’s DiemBFT v4 demonstrate the potential of pipelined, optimized consensus. Aptos has achieved ~210 ms block times by overlapping consensus with execution, and sustained around 20k TPS with ~1.3 s latency in stress tests. While Aptos uses a different approach, it similarly shows that with consensus refinements, sub-second finality is attainable even at high load.
Ethereum’s move to Proof-of-Stake underscored how quickly plain HotStuff-style voting hits a scalability wall: early Ethereum 2.0 designs struggled to handle more than about 900 validators before networking costs exploded. The leap to today’s 900 K-plus validator set came from two linked advances—signature aggregation and subdividing validators into attestation committees (subnets) that vote in parallel. NibiruBFT incorporates these concepts: validator clustering plus BLS aggregation shrink the consensus bottleneck so throughput can keep rising even as the validator set grows.
Estimated Performance Impact: By itself, the NibiruBFT upgrade (inclusive of the below techniques) is expected to improve block finalization times and throughput significantly over vanilla Tendermint. Thanks to better networking and signature handling, consensus overhead per block is reduced, so the network can handle more TPS before hitting latency limits. For instance, where a standard BFT network might slow down with >100 validators, NibiruBFT can target hundreds of validators without sacrificing ~2s finality. Overall, Nibiru anticipates on the order of ~50–100% faster block processing under load due to these consensus enhancements, forming the foundation for the dramatic gains seen in the combined system.
Notes: In practice, this means Nibiru can compete with or exceed the performance of other optimized BFT chains (Aptos, Solana) on the consensus front while preserving decentralization and instant finality.
4.2 | Validator Clustering – Hierarchical Consensus Scaling
Validator Clustering is a consensus scalability innovation that groups validators into sub-committees (clusters) to reduce communication complexity. In a traditional BFT consensus (like Tendermint/CometBFT), every validator must gossip votes to every other – an O(n²) communication cost that becomes a major bottleneck as n (number of validators) grows.
Validator clustering mitigates the quadratic messaging overhead that occurs in CometBFT: validators are partitioned into clusters that first reach internal consensus, and then each cluster contributes an aggregate vote to a second, higher-level consensus among cluster representatives. This means that in consensus engines that rely on this networking stack, the number of messages grows quadratically with the size of the validator set.
By grouping validators into dynamic stake-weighted clusters, Nibiru reduces worst case communication complexity from O(n2) to O(n+(n/k)2+k2), where n is the number of validators and k the number of clusters. With a big enough validator set where n>>k, this simplifies to O((n/k)2).
This dramatically reduces communication overhead. By localizing most messages within smaller groups, the network can scale to far more validators without overwhelming bandwidth or slowing down.

All clusters run a "mini-CometBFT" where validators within it can only see each other. The goal of a cluster is to reach a pre-commit state where 2/3 of the local stake agrees with the block proposed. In each cluster, validator votes are signed with BLS signatures. These signatures are combined within the cluster, forming a single compact signature that reflects the consensus of the cluster.

This compact signature is sent by the representative (whose selection is stake-weighted and rotative) to the x/clustering module, which will determine if a total stake-weighted supermajority has agreed. If so, the cluster signatures are aggregated and the block is finalized.
Comparable Benchmark: This approach is conceptually similar to committee-based consensus in large networks. For example, Ethereum 2.0 uses committees of ~128 validators for attestation duties, aggregating their signatures so that the wider network deals with only an aggregated vote per committee. This strategy has enabled Ethereum to successfully manage hundreds of thousands of validators with manageable overhead, something impossible with a naive all-to-all scheme.
Likewise, Algorand and Polkadot employ sortition or nominated subgroups to limit communications as the participant count grows. Research indicates that hierarchical or committee-based BFT can increase the validator count by an order of magnitude or more without impacting throughput.
Nibiru’s clustering specifically shows that if 100 validators is the practical limit for all-to-all Tendermint, using 5 clusters could support ~223 validators with similar load, and 10 clusters of ~316 validators – roughly a 3× increase in validator set size at equal performance. This is in line with other sharding and committee approaches (e.g. Facebook’s Libra envisioned 100+ validators with HotStuff by using quorums cleverly).
Estimated Performance Impact: Validator Clustering’s impact is measured in scalability and decentralization. Concretely, it reduces consensus messaging overhead by ~5–10× for large validator sets, which either translates to sustaining the same throughput with many more validators, or faster consensus (lower latency) with the current validator count. By cutting redundant network traffic, block proposal and voting rounds conclude quicker. For Nibiru, clustering is estimated to trim consensus latency by approximately 20–30% in a 100+ validator scenario and to enable 2–3× more validators to participate without degrading performance. This means Nibiru can increase decentralization (more validating nodes securing the network) while maintaining high TPS and <2s finality – a notable improvement over most Layer-1s where adding validators slows things down.
Notes: This innovation is still at the research/prototype stage; implementing two-layer consensus introduces complexity (e.g. handling cluster-level timeouts and ensuring cluster leaders accurately represent members). However, the theoretical benefits are clear.

4.3 | BLS Aggregation – Optimizing Signature Overhead
BLS Aggregation refers to using Boneh–Lynn–Shacham signatures to combine multiple validator signatures into one. In NibiruBFT, every block commit normally includes signatures from a supermajority of validators attesting to the block. With 100+ validators, these signatures (if using Ed25519 or ECDSA) become a significant burden – each must be broadcast and verified, contributing kilobytes of data and expensive crypto operations for every block.
This BLS signature approach reduces the block header size, making it possible to allocate more space for transactions. Moreover, the verification process becomes highly efficient, requiring just one operation to authenticate all validator signatures.
The x/clustering module plays a central role in this consensus algorithm by coordinating the aggregation of BLS signatures and determining whether a global, stake-weighted supermajority has been achieved. This makes it a critical mediator between local (intra-cluster) and global (inter-cluster) consensus. The x/clustering module is the key to a modular clustered consensus that reduces messaging overhead while maintaining upstream compatibility with the CometBFT core.
By combining validator clustering with BLS signature aggregation, NibiruBFT cuts both communication and verification overhead—enabling larger validator sets without compromising performance. More importantly, secondary geoclustering (specified in the Nibiru Lagrange Point whitepaper), groups validators by network proximity, further lowering consensus latency under ideal conditions. NibiruBFT’s targeted enhancements to the proven CometBFT engine deliver measurable performance gains today and pave the way for superior scalability and decentralization compared with traditional consensus mechanisms.
Comparable Benchmark: BLS signature aggregation is already deployed in Ethereum 2.0’s consensus. Ethereum’s beacon chain aggregates thousands of validator attestations per slot into a handful of BLS signatures, which was the key to scaling beyond ~900 validators limit to now over 700k+ validators. Researchers noted that without BLS, the messaging and verification load would cap the network, but aggregation “dramatically reduces the number of messages . . . and the cost of verifying them,” enabling scaling to hundreds of thousands of participants. In a similar way that Ethereum leverages signature aggregation to propagate attestations to the broader network, Nibiru leverages BLS signatures to propagate a single aggregated cluster vote for the intercluster consensus round.
In practical terms, BLS can compress, for example, 10,000 signatures into one, reducing signature data by ~10,000× (from ~ tens of MB down to 48 bytes). Another point of reference: Cosmos chains today typically forego aggregation (using Ed25519), which works fine for ~100 validators but wouldn’t scale well to more – projects like Dfinity and Algorand also leverage threshold or aggregated signatures to improve efficiency. Nibiru’s validator count (~50–100 and growing) is in the sweet spot where BLS aggregation yields clear net benefits in throughput.
Estimated Performance Impact: BLS aggregation is expected to cut consensus signature overhead by ~90%. Network-wise, instead of broadcasting N separate signatures, validators share one aggregated signature, significantly shrinking block gossip payloads. This directly improves block propagation times and validation speed. For example, if verifying 100 ECDSA signatures took, say, 100 ms of CPU time, a single BLS might take on the order of only a few milliseconds (though BLS involves pairings, it’s still far cheaper than dozens of separate verifications). Nibiru’s research notes “substantial performance gains . . . particularly in large validator sets” from BLS, as it reduces storage, bandwidth, and computation per block. This optimization has the potential to reduce block validation latency by ~10–15% and similarly increase the TPS ceiling, as it accelerates the consensus critical path (collecting and checking commits). The more validators, the bigger the impact – with future larger validator sets, this could be a make-or-break improvement.
Notes: Implementing BLS in consensus must be done carefully (to avoid issues like double-counting the same signature in gossip). NibiruBFT uses a two-stage commit aggregation scheme to ensure each validator’s vote is counted once. Another consideration is CPU overhead for BLS pairings; however, given modern optimizations and the relatively moderate validator count, this is manageable.
4.3 | Multi-lane Mempool and Block Design – Parallelizing Transaction Throughput
In traditional blockchains, all transactions are treated with similar priority. Usually, priority gas auctions (PGAs) determine which transactions are going to be added in the next block and their relative position within the block. This naive approach does not differentiate between different types of transactions, which may be an oversight, considering that some transactions are by nature more “critical” or “urgent.” As a result, the lack of differentiation forces these different types of transactions to compete with each other in the priority gas auctions.
Certain transactions are objectively more important and time-sensitive than others. For example, oracle updates or liquidations should be prioritized over less critical actions like NFT sales or token approvals, as they have a greater impact on blockchain health. Delays in oracle updates, for instance, can lead to incorrect protocol decisions, untimely liquidations, or even security exploits. For example, liquidations protect lending protocols and synthetic assets from becoming undercollateralized. If liquidations are delayed, bad debt can accumulate, putting the entire protocol and its users at risk.
To address this problem, NibiruBFT implements a multi-lane design that separates both mempool and the block structures into distinct sections with their own priority queue and block space. This design is facilitated by Block SDK, which exposes configurable parameters to control lane allocations. These parameters may also be used in the future for optimizations such as dynamic parameterization and adaptive resource allocation.
Default transactions such as routine swaps are delegated to a standard lane, while high-priority transactions (liquidations, oracle updates) are delegated to a dedicated fast lane. Similarly, MEV transactions are delegated to the fast lane, where competitive MEV gas wars are contained solely to this “MEV-lane.” It is important to note that priority-enshrined transactions (oracle updates/liquidations) will always be positioned at the top of the MEV lane, ensuring they will never be delayed or outbid by less urgent MEV strategies.
In NibiruBFT’s multi-lane block approach, if a lane isn't fully utilized, block space may be dynamically allocated to other lanes demanding more space. This would entail that, in real time, a block proposer monitors their mempool. If there is an imbalance between existing block lane allocations and local mempool composition, the block proposer would adjust the exposed laning parameters specified by Block SDK.

This approach improves the experience of network participants by making gas markets more efficient and ensuring that important operations such as liquidations are always executed, improving overall economic security.
For example, one lane might handle high-priority or time-sensitive transactions, while another handles simple sends or lower-priority actions. The nature of block proposals being exclusive to one node in the network at any given time means that managing mempool lanes and building a laned block is locally isolated. The block proposer is able to compose a block by simultaneously selecting transactions from their local independent mempool lanes. The block design can include separate sections or ordering for each lane, preserving each lane’s internal order while enabling parallel inclusion and validation. The goal is to avoid the inefficiencies of a one-size-fits-all mempool, where spam or one class of transactions can clog the whole pipeline. By contrast, multi-lane designs ensure predictable resource allocation and congestion management – certain transactions won’t starve others.
Comparable Benchmark: Sei Network (a Cosmos-based Layer-1 focused on high-performance trading) employs a concept of parallel lanes (via its Twin-Turbo consensus and specialized order-matching engine). Sei claims throughput of ~20,000 operations per second on their order-matching, roughly double Solana’s typical ~10,000 TPS and far above Ethereum’s ~20 TPS. This is achieved by separating order transactions into a fast lane optimized for processing them concurrently. Solana itself, while not explicitly using “lanes,” has a highly parallelized runtime (Sealevel) that effectively processes transactions concurrently if they don’t conflict on state, achieving massive parallel TPS in practice. Similarly, some Ethereum rollup designs and Layer-2 solutions use segregated transaction pools (e.g., one for regular transfers, one for batched withdrawals, etc.) to maximize efficiency. Polygon’s throughput research and others exploring multi-dimensional fee markets also recognize that isolating different transaction types (with different gas or priority parameters) can smooth performance. Nibiru’s approach is in line with these – by dividing the mempool, it can treat, say, a surge of oracle votes separately from a surge of DEX trades. The comparable result is improved throughput and latency consistency even under heavy mixed workloads.
Estimated Implications: Multi-lane mempool and block design is expected to improve throughput and reduce latency under congested conditions by a significant margin. In scenarios where one class of transactions would bottleneck the pipeline, lanes ensure others still get processed. It is estimated that under high load (e.g., an NFT mint craze concurrent with DeFi trades), Nibiru could see ~2× higher effective TPS with lanes compared to a single queue, since the two lanes can progress in parallel up to a point. Additionally, priority lanes can guarantee low-latency for critical transactions – effectively reducing tail latency for those txs by perhaps 50% or more in busy periods (they skip ahead of the bulk traffic). Empirical benchmarks from Sei suggest real-world Layer-1s can hit tens of thousands of TPS with specialized parallelization, so Nibiru’s multi-lane design, combined with its parallel execution engine (next section), is poised to reach similar territory. Another tangible impact is more stable fees: by preventing one category of tx from spiking fees for all, the fee market in each lane is more predictable. This could reduce fee spikes and improve user experience during traffic bursts.
Notes: Implementing multiple mempool lanes requires careful handling to avoid consensus breaking transaction ordering rules. Nibiru will need to ensure that cross-lane interactions (if any) are well-defined – for instance, if a transaction in lane A depends on one in lane B, the design must account for it (this might be solved by restricting lanes to independent transaction types). The block proposer logic becomes more complex, as it must pull from each lane fairly and possibly in parallel.
4.4 | QUIC Networking – Low-Latency Block Propagation
In most blockchains, validators use TCP/IP to communicate. Despite being a well-known communication protocol, it has difficulties managing complex communication networks. The QUIC protocol overcomes some networking problems that high-throughput blockchains usually face, such as lost connections, delays, or inconsistent data flow.
QUIC is a modern protocol (built atop UDP) that offers several performance advantages: reduced handshake latency (often 0-RTT connection setup on repeat connections), no head-of-line blocking (independent streams so packet loss on one stream doesn’t stall others), built-in TLS encryption, and efficient congestion control for multiplexed streams.
QUIC provides three key benefits:
- Stream Multiplexing: In traditional transport protocols like TCP, all data is sent over a single stream. This means that if a packet is lost or delayed, even if it's unrelated to other data being sent, all subsequent packets must wait until the missing packet is retransmitted and received. This is known as Head-of-Line (HOL) blocking. This becomes especially problematic in distributed systems or blockchain networks, where different types of messages such as transactions, consensus votes, and block proposals may be transmitted simultaneously. Imagine a stablecoin depegs on another chain, but the oracle update is delayed due to Head-of-Line (HOL) blocking (for example, if block transmission is stuck and consensus can't proceed). This can lead to catastrophic liquidation cascades or result in bad debt. With QUIC, if some messages are delayed, others can still go through as each stream has its own flow, so if a packet is lost or delayed in one stream, other parallel streams continue running.
- Reduced connection overhead: Connecting nodes is much faster using QUIC than TCP/IP. QUIC incurs far fewer round times (RTTs) upon new connections and reconnections compared to TCP/IP (1 and 0 vs. 3-4 and 2-3, respectively).
- Connection Migration: If a validator IP address changes (like switching WiFi), the connection still works without needing to start over. QUIC preserves session state, so there’s no handshake delay or performance hit associated with TCP’s Slow Start. While TCP includes optimizations like Hybrid Slow Start algorithms to improve bandwidth estimation during startup, it still requires a full handshake and congestion window reset upon reconnection. In contrast, QUIC maintains session parameters across connection migrations, avoiding these inefficiencies and enabling more reliable performance.

Comparable Benchmark: Solana was an early adopter of QUIC in a major Layer-1, shifting from raw UDP (which lacked congestion control) to QUIC for its data plane. This change proved “battle-tested,” boosting network throughput and stability and enabling thousands of TPS with a global validator set. While precise metrics remain internal, QUIC is credited with cutting block propagation times and reducing packet loss under load.
We can also look at libp2p-based networks (e.g., Ethereum’s future phases and Polkadot) now support QUIC, with experiments reporting 30–40% lower latency in peer-to-peer message propagation versus TCP, thanks to eliminated head-of-line blocking. Nibiru’s adoption of QUIC aligns with these trends—positioning its network to efficiently handle traffic spikes and large-block data while benefiting from proven improvements in latency and bandwidth utilization.
Estimated Performance Impact: Integrating QUIC is expected to reduce network latency for block and vote propagation by on the order of tens to hundreds of milliseconds. In practical terms, this might mean shaving, say, 100ms off the time it takes for a new block to reach most validators, which is significant when block times are ~1-2 seconds. By cutting the TCP 3-RTT handshake to 1-RTT or 0, validators that need to reconnect or gossip with new peers do so faster. The elimination of head-of-line blocking means a single dropped packet won’t hold up an entire block’s delivery – thus consensus messages (pre-votes, pre-commits, block part propagation) flow more smoothly, avoiding delays.
Adopting QUIC could potentially enhance overall block propagation speed by around 20–25%, and improve resilience such that performance under packet loss (e.g. 1% loss) might degrade much less (perhaps only a few percent slowdown, versus severe slowdowns under TCP). The throughput impact is indirectly higher TPS: faster propagation -> quicker consensus -> ability to have lower block times or fit more blocks per second. Nibiru’s sub-2 second finality is more robust under heavy loads with QUIC. If the network were to attempt 1s or sub-1s block times, QUIC is almost a necessity to succeed. It’s reasonable to attribute a several hundred TPS increase capacity just from networking efficiency, and much smoother scaling as more validators join (since QUIC handles many connections in parallel better).
Notes: The network layer is often overlooked, but it becomes critical at high TPS – broadcasting 10,000+ transactions per second worth of data is non-trivial. QUIC’s multiplexing and flow control help prevent congestion collapse by adapting to network conditions.
5 | Execution Layer: Adaptive Reordered Execution – Dynamic Parallel Transaction Processing
Processing transactions in parallel is a challenge, as blockchains are essentially state machines where any transaction changes the global state (account balances, smart contract storage, etc.). To preserve determinism, nodes have to execute transactions in a way that preserves serializability, ensuring they all arrive at the same final state, even if transactions are processed in parallel.
There are different approaches to solve this like optimistic execution, deterministic execution or basic adaptive execution each of them with its trade-offs.
- Optimistic execution assumes that transactions will not conflict. If there is any conflict the transactions involved are rolled back. This approach is quite inefficient, as in periods of high activity transactions will try to access the same resource multiple times, rolling back a lot of transactions.
- Deterministic execution precomputes all transactions to identify potential conflicts beforehand and orders the block accordingly to avoid rollbacks. Although this algorithm prevents rollbacks, validators running this execution engine need high computational power, which can lead to centralization.
- Basic adaptive execution engines like Block-STM partially solve the issues of both deterministic and optimistic approaches, but under high network activity some transactions may be re-executed several times, especially in DeFi, where many transactions need to access the same resource. While transaction re-execution can be performant with parallel execution frameworks like Block-STM, the reliance on multi-versioned data structures (MVDS) introduces computational overhead. This increases the hardware requirements for validators, raising the barrier to entry.
Nibiru adaptive execution engine aims to reduce these trade-offs through a novel strategy: rather than reactively managing dependencies, as with multiversion concurrency control (MVCC) mechanisms, Nibiru Adaptive Execution anticipates it by optimistically minimizing contention before execution. As a result, Nibiru’s novel Adaptive Execution Engine is expected to be both more efficient and less resource intensive.
5.1 | Nibiru Adaptive Execution
Adaptive Execution is Nibiru’s novel approach to parallelizing transaction execution, inspired by Pipeline-Aware Reordered Execution (PARE) techniques from high-frequency trading. It can be seen as a hybrid of optimistic and deterministic concurrency control. This approach dynamically reorders transactions based on real-time contention analysis, prioritizing operations that are less likely to conflict.
Nibiru plans to initially employ optimistic parallel execution: assume transactions don’t conflict, run them in parallel, and if a conflict (e.g., two tx writing the same state) occurs, rollback and serialize those conflicts. This works well when contention is low, but under heavy contention (like many users interacting with the same DeFi pool), frequent rollbacks hurt performance. Adaptive Execution improves on this by reordering transactions based on estimated conflict risk, effectively scheduling dependent transactions in a safer sequence while still executing independent ones in parallel.
The adaptive execution engine monitors which resources are most frequently used to increase the contention score of transactions accessing them. It then separates transactions into block segments that are independent (transactions that don't conflict with each other), these block segments are called reordering blocks (RB). As transactions within an RB should be independent, they can be safely executed in parallel. These reordering blocks are sorted based on contention scores, with highly contended operations executed first to minimize waiting time for other transactions.
This makes Adaptive Execution particularly effective in high-contention environments like those typical in crypto, where recent researchers (e.g., MegaETH) estimate an average of just ~2.75 parallelizable transactions per block. By identifying and executing the most contended transactions first, Nibiru reduces bottlenecks that would otherwise stall execution, uncovering concurrency that traditional models often miss. This results in higher throughput even under heavy load, where conventional engines tend to degrade into mostly serial execution.
Let's see an example of creating a block:

Step 1: Group and Reorder Blocks
The first step for the scheduler is to divide the block into reordering blocks. The scheduler will iterate through existing reordering blocks and all transactions already placed within them.
The scheduler will compare the read and write sets of the new transactions with the read and write sets of the existing transactions. If there are any intersections between the new and existing read and write sets, the transactions cannot be added to the reordering block. If no existing reordering blocks are viable candidates, the scheduler will create a new reordering block containing the current transaction.
Evaluate T1:
- As it is the first transaction there are no dependencies.
T1: RB1 is created -> RB1 = [T1]
Evaluate T2:
- T2 (R: B, W: C)
- T1 has W: B conflict with T1, can't be added in RB1.
RB2 is created -> RB2 = [T2]
Evaluate T3:
- T3 (R: D, W: E)
- No conflicts with T1 or T2 → can be included in both RB1 and RB2.
RB1 = [T1, T3]
Evaluate T4
- T4 (R: F, W: G)
- No conflicts with T1 or T2 → can be included in both RB1 and RB2.
RB1 = [T1,T3,T4]
Evaluate T5
- T5 (R: C, G | W: H)
- T2 has W: C → conflict with R: C → can't be added in RB2
- T4 has W: G → conflict with R: G → can't be added in RB1
RB3 = [T5]
Step 2: Calculate the contention scores of each transaction:
In this example, the number of times a slot is accessed determines its contention score, but different heuristics can be applied.
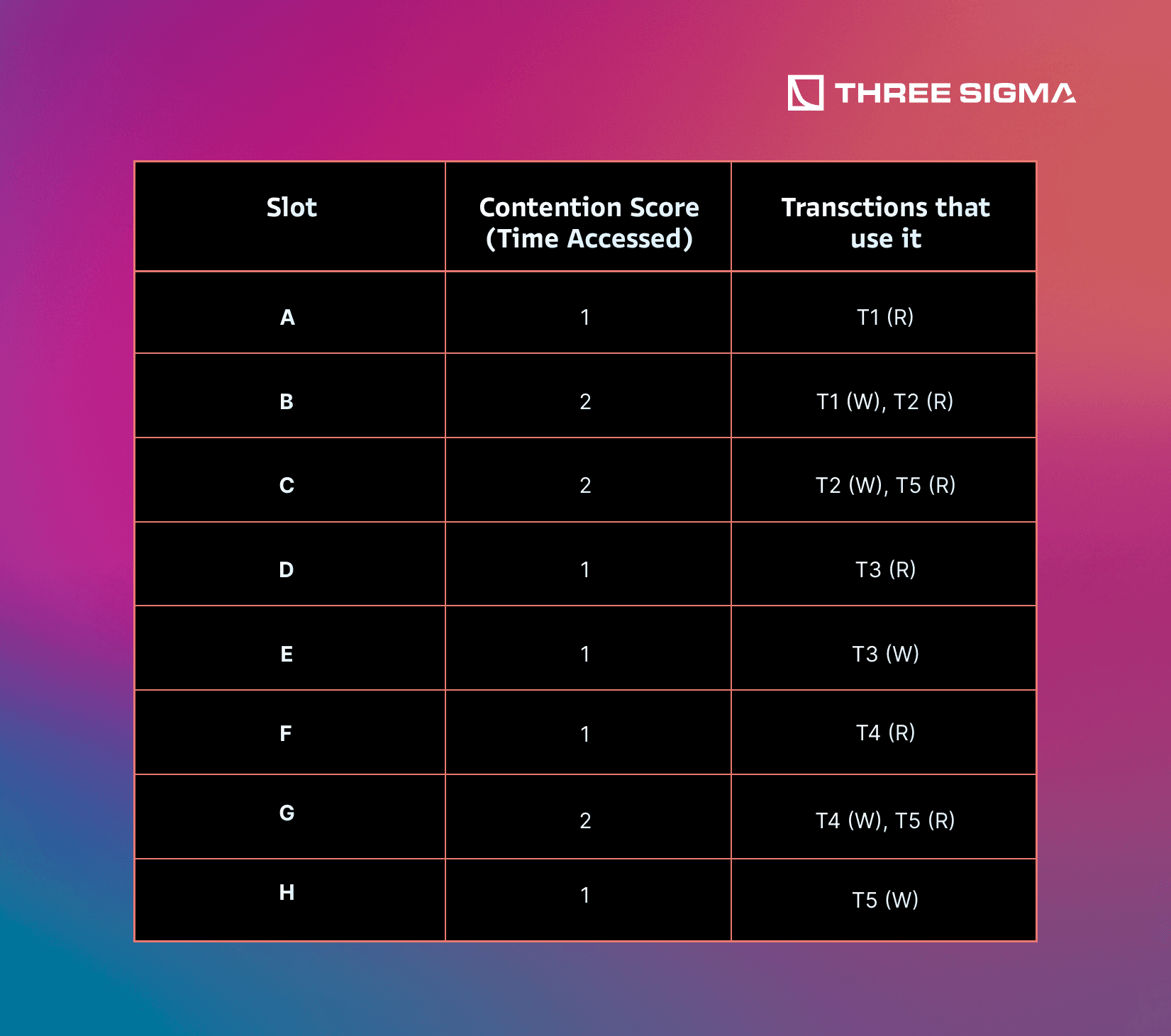
Step 3: Calculate the contention scores of each reordering block:
The contention score of a RB is the sum of the contention score of each transaction included in the RB. Again, different heuristics could be applied to optimize this.

Step 4: Sort reordering blocks:
Once the contention score of each RB is calculated, the RBs are sorted from highest contention score to lowest in order to minimize waiting times for other transactions.

The reordering block is considered an atomic unit by the scheduler, which only looks at block-level contention score. Any inherent dependencies are encoded in the RB structure, so no new dependencies are created regardless of the order of the RBs.
In short, it adapts to workload patterns: maximizing parallelism when contention is low and, when contention is high, reordering and serializing transactions as needed to avoid wasted work.
Comparable Benchmark: This approach can be compared to Aptos’s Block-STM vs Solana’s Sealevel. Aptos uses an optimistic parallel execution (Block-STM) with a conflict-checking mechanism, whereas Solana uses a pessimistic scheduler (static analysis of account locks) to run non-conflicting transactions in parallel. Aptos demonstrated that even with optimistic concurrency, careful design can achieve extremely high throughput – over 160k TPS in benchmarks on an 8-core machine, and up to 193k TPS in an experiment with 10k transactions in parallel. The Hackernoon analysis found Block-STM could hit ~137k TPS on 8 threads with low contention, and still >15k TPS on highly contentious (sequential) workloads, whereas Sealevel peaked around ~107k TPS in those tests.
Another comparison is Monad (an upcoming high-performance EVM) which also uses optimistic parallel execution; like Nibiru, they aim to reorder or manage conflicts smartly to achieve huge throughput gains. Overall, the state-of-the-art indicates that parallel execution can improve throughput by an order of magnitude or more over sequential execution, given sufficient CPU cores.
Estimated Performance Impact: Adaptive Execution is likely the single biggest contributor to raw TPS gains in Nibiru Lagrange Point. By leveraging multicore processors, Nibiru can process many transactions at once. If Nibiru EVM already does >10,000 TPS on a single thread today, then parallel execution across (say) 8–16 cores could theoretically push that to 50k–100k+ TPS range under ideal conditions (linearly scaling with cores). Even under contention, mainnet throughput should consistently reach multi-thousand TPS levels, representing a substantial improvement (many current Layer-1s struggle to maintain even 1k TPS in real conditions).
For example, with Adaptive Execution avoiding most rollback penalties, a contentious workload (like a popular AMM contract) might sustain significantly higher throughput—around 5× in some cases—compared to naive optimistic execution, because the scheduler will serialize just enough (utilizing sliding windows) to prevent thrashing. Meanwhile, highly parallel workloads (lots of independent transactions) will approach linear scaling – e.g. 8 cores giving nearly 8× throughput. In terms of latency, reducing conflicts means fewer tx have to be re-run or delayed, so tail latency drops; block execution completes faster, helping keep block time low. Combined with the pipeline between consensus and execution, Nibiru could potentially shrink its block processing time by ~50% or more. Aptos’s ~0.2s block time achievement is a testament to what full parallelism + pipelining can do. Nibiru’s Adaptive Execution, while complex, is expected to yield a multi-fold increase in TPS (up to 10× over pre-Lagrange performance for certain workloads) and robust low-latency processing even under heavy dApp usage.
Notes: An adaptive engine must intelligently decide when to reorder or fall back to sequential execution. Nibiru’s design will employ heuristics or conflict-graphs to do this optimally. There is ongoing research to refine these algorithms. Another point is that this execution model overlaps with consensus – Nibiru will likely pipeline execution concurrently with consensus (execute next block while the current block is being decided), similar to what Aptos and Solana do, to fully utilize time. This demands careful engineering but pays off in throughput.
6 | Multi VM: EVM and Wasm on a Unified Layer
Traditionally, only one virtual machine (VM) is supported in a blockchain, this limits developers and their applications. Nibiru Multi VM addresses this limitation by embedding multiple VMs into the base layer. By doing so, developers can leverage the strengths of one VM and mitigate the disadvantages of the other by combining them.
This allows developers to deploy Solidity smart contracts and Rust CosmWasm contracts on the same chain, with seamless interoperability. From a performance standpoint, Multi VM means the chain can handle diverse workloads without external bridging – tokens and calls move between VMs natively. This avoids the overhead of cross-chain communication (which typically involves multisigs or light clients and can take minutes) and instead enables near-instant cross-VM interactions.
Because the EVM and WASM environments run in parallel within Nibiru, the system can potentially execute transactions in both VMs concurrently, leveraging separate resources for each. It also allows horizontal scaling by specialization: certain logic might run more efficiently on one VM versus the other, and the chain can optimize accordingly.
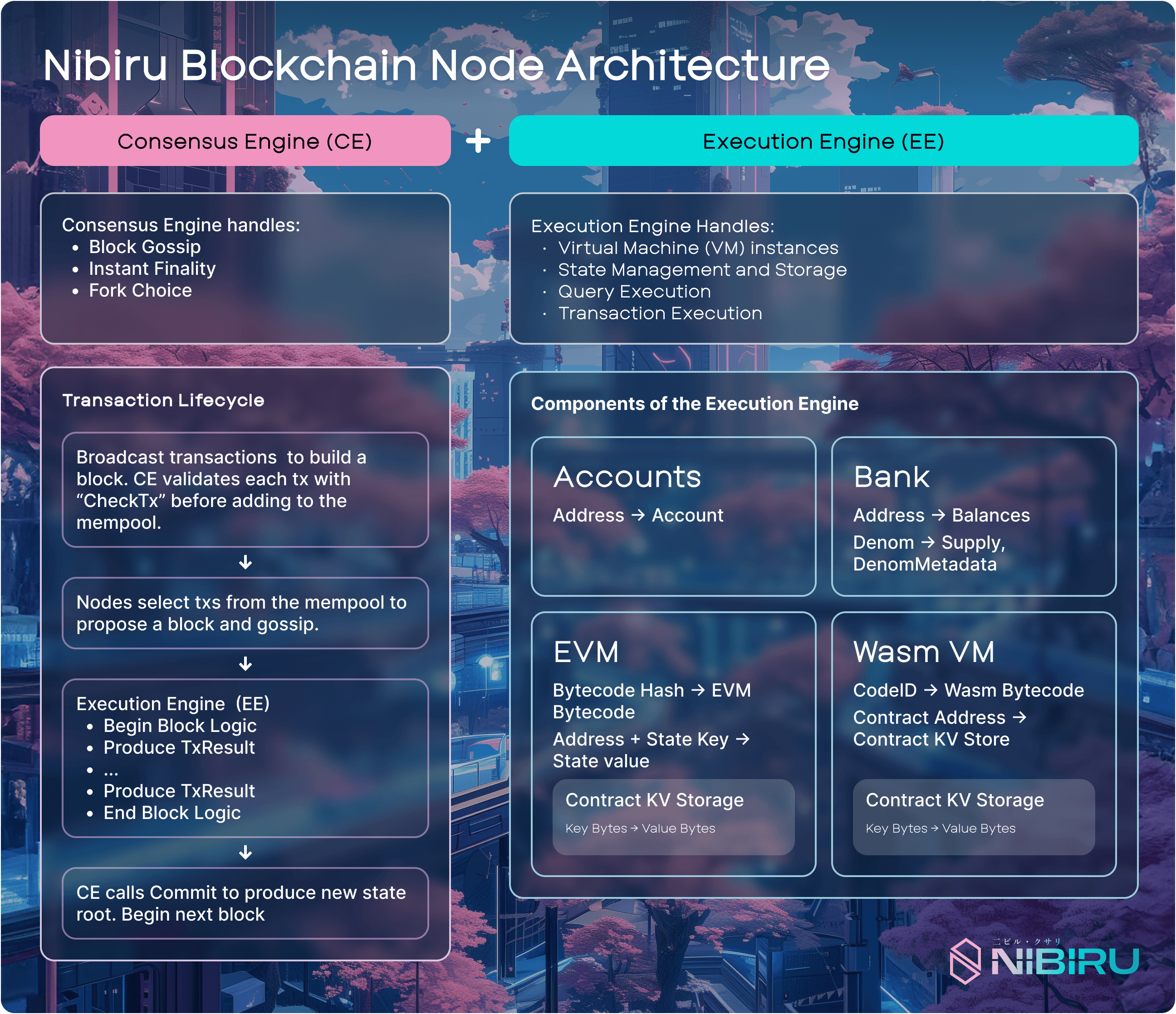
6.1 | Nibiru Wasm:
The Wasm VM supports Rust-based contracts with built-in security advantages (memory safety, reentrancy protection). Developers can choose the right VM for their use case without compromising composability.
6.2 | Nibiru EVM:
Nibiru Lagrange Point introduces native EVM support, running directly on the base layer (not as a rollup or sidechain). This implementation is fully bytecode compatible and supports standard Ethereum tools (MetaMask, Hardhat, JSON-RPC), offering developers a familiar environment with better performance and shared liquidity across VMs.

6.3 | Cross VM applications:
Unlike other Layer-1s with siloed execution environments, Nibiru enables cross-VM interoperability. Applications can combine EVM for frontend logic, Wasm for collateral management, and (future) MoveVM for risk logic, all in a single transaction.This breaks down the tradeoff between developer comfort and liquidity access, as teams can build in the VM they know best while still being able to access cross-VM liquidity.
Comparable Benchmark: Other projects have pursued multi-VM or hybrid architectures: Polygon Supernets / Avalanche subnets allow different chains for EVM and others under one umbrella, but those still function as separate chains (bridged). Cosmos Hub with Ethermint (Evmos) and Fuel with Ethereum have explored co-existence of VMs. Perhaps the closest in spirit is Aptos/Sui’s Move VM alongside potential future WASM support – while not there yet, the idea of supporting multiple contract languages on one chain is gaining traction.
Since direct benchmarks are scarce (Multi VM is cutting-edge), the focus is on the elimination of bridge overhead. Normally, if you wanted an Ethereum dApp to talk to a CosmWasm contract, you’d bridge tokens across chains, incurring latency (on the order of 6–60 seconds or more) and throughput limits. With Nibiru’s Multi VM, those interactions happen in a single block, taking advantage of general purpose, cross-VM precompiles. So one can consider the performance improvement as a near 100% reduction in cross-environment latency – going from, say, a 1-minute cross-chain transaction to a 1.8-second on-chain call.
Estimated Impact: Multi VM’s impact can be described as improved versatility. It eliminates entire categories of latency: cross-VM calls that used to go over bridges now happen within one block (improvement from minutes to seconds). It also means users don’t wait for finality on two chains – everything finalizes on Nibiru, improving the user experience speed. Another performance aspect is developer productivity (time-to-deploy); by using the same chain, development cycles are faster which indirectly speeds up network growth and usage. From the end-user perspective, Multi VM ensures that using an EVM dApp on Nibiru is as fast as on any optimized Layer-1 (with the added benefit that if that dApp wants to use a CosmWasm contract, it can without slowdown).
Notes: Combining multiple VMs requires careful consensus and state management to ensure consistency (one unified state or linked state between EVM and WASM). Nibiru handles this with a unified account system and FunToken mechanism to allow assets to move between EVM and native modules without trust assumptions.
7 | Future Developments
This is not the final infrastructure upgrade for the Nibiru blockchain - there are plans to add more VMs to the base layer and enhance security.

7.1 | Future VM support:
Nibiru is expanding its Multi VM architecture to natively support additional virtual machines at the base layer, specifically the Solana VM (SVM) and Move VM. This means that beyond the existing Ethereum Virtual Machine (EVM) and WebAssembly (Wasm) environments already running on Nibiru, the chain will be capable of executing smart contracts written for Solana’s Sealevel runtime and those using Move (the language originated from Diem/Aptos). In practice, this adds tremendous flexibility: developers from Solana and Move ecosystems can deploy their programs directly on Nibiru without needing external bridges or layer-2 rollups. Nibiru’s design emphasizes seamless interoperability between these environments – Wasm, EVM, and future VMs like Solana’s and Move’s – all on one chain
By integrating SVM and MoveVM at the base layer, Nibiru would essentially become a polyglot platform where heterogeneous smart contracts coexist and interact under a single consensus and state. This capability would allow assets and data to flow between Solana-based programs, Move-based modules, and EVM contracts internally.
Comparable Benchmarks: Multi VM and cross-VM compatibility is an emerging trend as blockchains strive to attract diverse developer communities and improve performance:
- Aptos (Move VM): Aptos is a Layer-1 built around the Move VM and a parallel execution engine (Block-STM). It has demonstrated significantly higher throughput than traditional single-threaded chains, reportedly aiming for tens of thousands of TPS in stress tests, far above Ethereum’s ~15 TPS. For example, Solana – which uses a comparable parallel execution approach – has “theoretically validate[d] 50,000 to 65,000 transactions per second (TPS)” under test conditions, underscoring the performance potential of parallelized VMs. Move-based chains like Aptos and Sui similarly leverage concurrency to achieve high throughput.
- Solana Sealevel and Neon EVM: Solana’s Sealevel VM (SVM) is known for its ability to execute many transactions in parallel by using a BPF-based runtime and an account-level concurrency model. This design has made Solana one of the highest throughput chains in practice. A noteworthy cross-VM effort is Neon EVM, which runs Ethereum-compatible EVM bytecode as a program on Solana. Neon’s deployment on Solana (mainnet launch in July 2023) proved that foreign VMs can run on a different base chain, though with some performance overhead. In late 2023, Neon EVM achieved a peak of ~730 TPS on Solana’s mainnet – a major milestone as “the first parallelized EVM” in Solana’s ecosystem. This throughput, while lower than native Solana programs due to translation overhead, still outpaces Ethereum Layer-1 and illustrates the feasibility of mixing VMs.
- Multi VM Support in Other Networks: A number of projects have started supporting multiple contract platforms to broaden their appeal. For instance, Astar Network (a Polkadot parachain) runs both an EVM and a WASM smart contract runtime in parallel. The Astar team notes this dual-VM approach is a “key success factor for any emerging Layer-1 blockchain”, as it offers flexibility for developers to choose their preferred environment. In the Cosmos ecosystem, several chains are combining CosmWasm (Wasm-based contracts) with an EVM module (e.g. Cronos, Injective’s upcoming enhancements) to similar effect.
Notes: While the prospects are exciting, implementing SVM and MoveVM at the base layer comes with important considerations and challenges:
- Engineering Complexity: Integrating additional VMs directly into the chain’s core is non-trivial. The team must implement or incorporate a Solana runtime (BPF execution engine, bytecode verifier, account model) and a Move VM, and ensure they operate deterministically under Nibiru’s BFT consensus. Each VM has its own transaction format and state management: for example, Solana transactions specify upfront which state accounts they will read/write, and Move transactions involve resource assets and global storage in a particular way. Nibiru will need to adapt these to its Cosmos-SDK-based architecture without breaking consensus or security. Achieving native compatibility (not via an external bridge or sidechain) means thoroughly mapping Solana’s and Move’s semantics onto Nibiru’s infrastructure, which could require custom modules and extensive testing.
- Security Considerations: Each additional VM broadens the attack surface of the blockchain. Bugs or vulnerabilities in the Solana VM implementation or Move VM could have chain-wide implications. For instance, Solana’s runtime deals with bytecode programs and C/C++-level memory safety (BPF programs), which might introduce different classes of vulnerabilities compared to EVM’s higher-level bytecode. The Move VM emphasizes safety (resources cannot be double-spent, memory safety by design), but it’s newer and less battle-tested in a Cosmos context. For each additional VM, Nibiru’s team will need to conduct extensive audits and perhaps run these new VMs in guarded modes initially. It’s also worth noting that maintaining multiple execution environments will require ongoing upgrades as each underlying ecosystem evolves (e.g., Solana might introduce new BPF instructions or syscalls, Move language might get new features) – Nibiru must keep pace to remain fully upstream compatible, all without introducing consensus-breaking changes.
7.2 | Quantum ready signatures:
Quantum computing is a threat for today's blockchain security. While classical cryptography such as Elliptic Curve Digital Signature Algorithm (ECDSA) and Keccak-256 can withstand current threats, they risk becoming obsolete once quantum machines become accessible and achieve sufficient qubit counts.
The Quantum-Resistant Cryptography initiative at Nibiru focuses on lattice-based solutions, particularly the Modular Lattice Digital Signature Algorithm (ML-DSA), as a replacement for vulnerable ECDSA signatures.
ML-DSA derives its security from two lattice-based problems:
- Modular Learning With Errors (MLWE): A problem involving finding a secret vector and error vector given a random matrix and result vector
- Module Short Integer Solution (MSIS): Finding a short non-zero vector that satisfies specific mathematical constraints
These problems are believed to be resistant to quantum computing attacks, including Shor’s algorithm, making ML-DSA a promising candidate for post-quantum blockchain security.
The core idea is that while a sufficiently advanced quantum computer could crack elliptic-curve cryptography (using Shor’s algorithm to derive private keys from public keys), lattice-based schemes rely on mathematical problems (like the hardness of lattice short vectors or module-SIS/LWE problems) that are believed to be resistant to quantum attack.
The security impact is that even if a quantum computer capable of breaking 256-bit EC keys emerges a decade or two from now, Nibiru’s accounts and state would remain secure – an attacker couldn’t simply forge signatures to steal funds or falsify blocks. This quantum-readiness adds a layer of resilience that few networks currently have, essentially future-proofing Nibiru’s cryptography. It’s an ambitious upgrade, touching the very foundation of how identities and transactions are authenticated on the chain.
Estimated Impact: Embracing quantum-resistant signatures will have far-reaching strategic and security benefits for Nibiru. The most obvious impact is the longevity of security: Nibiru’s transactions and state could remain secure even in the face of quantum computing breakthroughs. This assures users that the value and contracts secured by the chain won’t suddenly become vulnerable due to external advances in computing. Such assurance is not just theoretical – it could become a strong selling point for certain use cases.
For example, institutions or governments that are wary of quantum threats (which could be relevant for things like central bank digital currencies or long-term asset tokens) might prefer a platform that’s already quantum-safe. Nibiru could market itself as a blockchain “built for the next century” where even the advent of quantum computers won’t necessitate a chaotic migration of keys. Moreover, by doing this early, Nibiru can iron out the kinks in implementation well before quantum attacks are a practical concern. This includes optimizing signature verification, handling larger keys, and updating wallet infrastructure — all of which can be done methodically rather than under pressure.
8 | Innovation-Impact Evaluation
The table below summarizes each innovation, with a brief description, references to comparable benchmarks or research, the estimated performance impact, and additional notes:
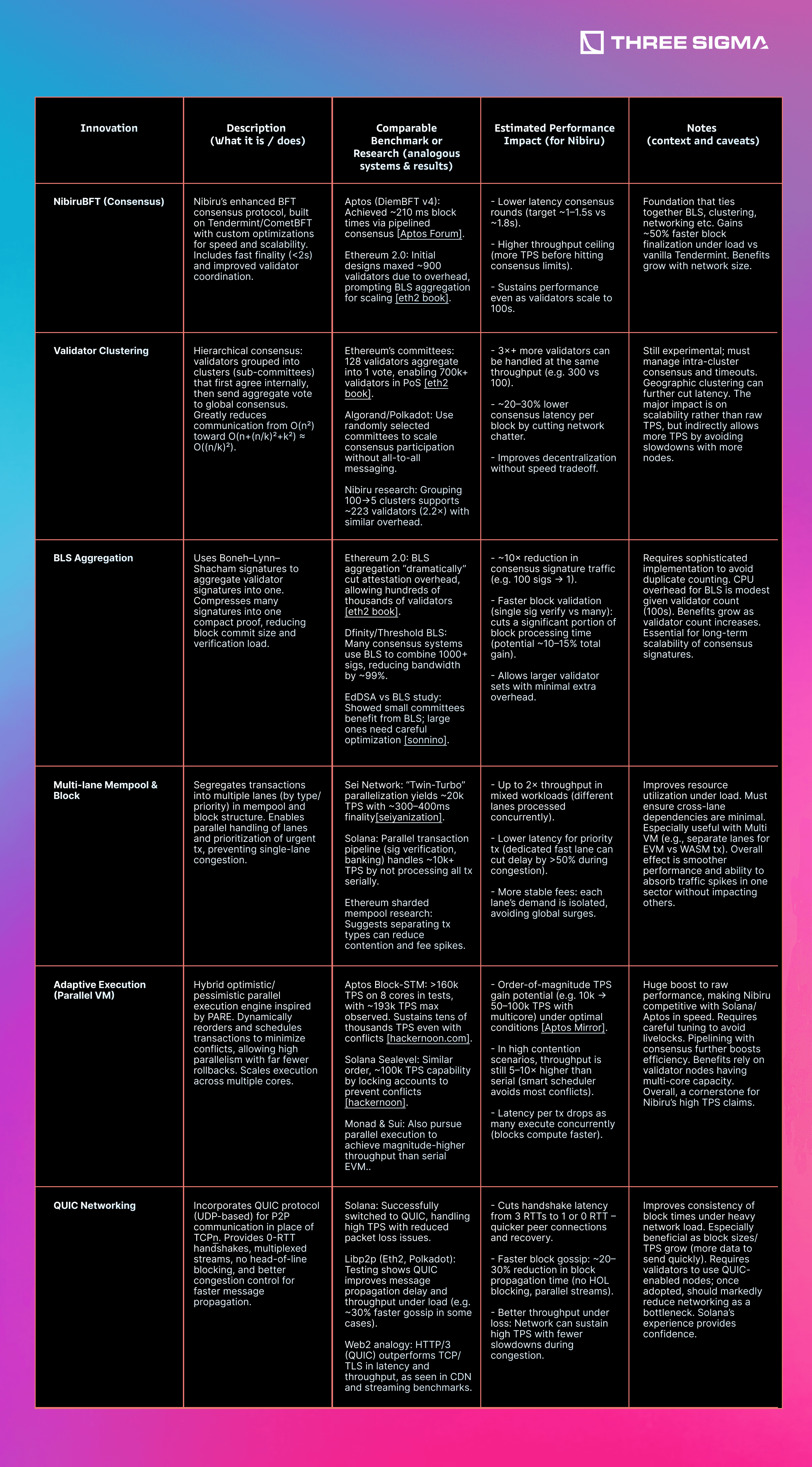
Combining all of these innovations, Nibiru Lagrange Point is positioned to achieve a step-change in performance. Each component tackles a different layer – consensus, networking, execution, mempool, etc. – and their effects are largely complementary. By removing bottlenecks across the entire stack, the overall system throughput and latency improve. We can attempt to quantify an overall improvement figure:
8.1 | Throughput (TPS)
Prior to Lagrange upgrades, Nibiru (like typical Layer-1s) might handle on the order of a few hundred to a couple thousand TPS in realistic conditions. With the EVM optimization, >10,000 TPS was already achieved on single-thread. Now, with Adaptive Execution (parallelism) and Multi VM, the network can leverage multiple cores and multiple execution contexts. It is reasonable to expect tens of thousands of TPS capability. In fact, the design goal is to approach Web2 scales – on the path towards 50k–100k TPS overall. For context, Visa peaks at ~65k TPS, and cutting-edge research like MegaETH targets ~100k TPS with sub-millisecond latency. Nibiru’s improvements put it within this high-performance league.
An estimation would be an aggregate 5-10× throughput increase over the current Nibiru (pre-Lagrange) architecture. So if current is ~2k TPS, Lagrange could push ~10k-20k+ sustained; if current is 10k (as per the EVM test), it could go to ~50k+. This is on the order of 1–2 orders of magnitude higher TPS than mainstream chains like Ethereum today (which does ~20–30 TPS), and clearly surpasses many existing Layer-1s.
8.2 | Latency and Finality
Nibiru already has instant finality (~1.5–2.0 seconds). The upgrades aim to drive this below 1 second in many cases. With faster consensus (BLS, clustering, QUIC) and faster execution (pipelined parallel processing), the block time can shrink. End-to-end transaction confirmation times are anticipated to be around 1 second or less under optimal network conditions – roughly a 50% reduction in latency versus current ~2s, and far better than networks that have 5-12s block times (or longer finality). This means Nibiru can approach real-time feedback for users, an important milestone (while perhaps not sub-millisecond like MegaETH’s aspiration, certainly low enough for most applications).
8.3 | Scalability & Decentralization
Perhaps the most profound overall impact is that Nibiru can scale without sacrificing decentralization. Many systems achieve high TPS by using few nodes or centralized sequencers. In contrast, Nibiru’s architecture is built to handle hundreds of validators and heavy loads simultaneously. The overall improvement here is qualitative: the network can grow (more validators, more diverse apps) and continue to perform. The clustering and BLS ensure that adding more validators (for security) does not linearly degrade performance as it normally would. In effect, the Lagrange Point could enable Nibiru to triple or quadruple its validator count with negligible hit to throughput, a huge win for security and decentralization.
Taking these together, the overall performance improvement of Nibiru Lagrange Point is transformative. Throughput is expected to improve by approximately 5×–10×, with latency (finality speed) improving by around 2×, in addition to notable increases in capacity and efficiency. In practice, this means Nibiru could handle workloads that previously would have overwhelmed it or any similar chain – from high-frequency trading with thousands of TPS, to gaming and metaverse applications requiring instant response, all on one platform.
9 | Ecosystem Highlights
As a Multi VM smart contract platform, Nibiru dissolves the technical barriers that traditionally fragment ecosystems, allowing dApps optimized for different VMs to trustlessly interact and share liquidity. This interoperability ensures that any application can benefit from being deployed on Nibiru, gaining access to new audiences while providing users with useful utility.
Nibiru Chain launched its public mainnet in early 2024 with several in-house decentralized applications showcasing its capabilities. At launch, users could mint and trade NFTs on Dropspace, register “.nibi” domains via Nibiru ID, play a Web3 chess game (Chess3), and even explore tokenized real estate via Coded Estate. By April 2024, the team touted a strong developer response – over 100 projects and companies were reportedly building on Nibiru. However, not all of these early initiatives survived into 2025. Some of the earlier apps from launch (such as Dropspace’s NFT marketplace, the Nibiru ID naming service, and the Chess3 game) have since been discontinued or deprioritized as the ecosystem matured. This natural churn reflects an adaptive evolution.
Despite the turnover of some early projects, Nibiru’s ecosystem is growing in breadth and maturity. The emphasis has moved toward third-party applications – often protocols originally built for EVM-based chains – that are now deploying on Nibiru. Crucially, Nibiru implemented a major upgrade (called Nibiru V2) to introduce full Ethereum Virtual Machine (EVM) compatibility within a year of launch.
One key differentiator between blockchains is which primitives (core DeFi and NFT building blocks) are available at or soon after launch. Primitives include decentralized exchanges (DEXs), lending/borrowing platforms, staking mechanisms, stablecoins, NFT marketplaces, etc. Many older platforms started with very few such dApps, whereas newer entrants often coordinate launches of multiple applications to bootstrap activity.
Today, Nibiru’s ecosystem features a range of active projects and upcoming protocols that signal a maturing platform. Below are some key highlights of the current landscape, reflecting the shift toward third-party and EVM-centric development:

9.1 | DeFi:
The DeFi suite covers every base and spans multiple verticals, including DEXs, lending markets, real yield protocols, and on-chain derivatives.

On the DEX front, there is Galaxy Exchange (cross-chain bridging and swap protocol), Astrovault (cross-chain value capture spot DEX), Oku Trade (powerful DEX aggregator and Uniswap V3 deployer), and Swify (concentrated liquidity DEX) enabling traders to interact with liquidity across multiple pools through a user-friendly interface connected to Nibiru’s EVM. SilverSwap, which is coming soon, adds a Uniswap V4-inspired AMM, leading into the modular DeFi narrative.
When it comes to real yield, Syrup Finance brings institutional lending to Nibiru's ecosystem via LayerZero. Users can swap into SyrupUSDC (a token backed by an overcollateralized portfolio of short-duration, fixed-rate loans issued to top-tier crypto institutions). This setup delivers consistent, high-yield returns sourced from real credit activity. This “real yield” model matches the fee-sharing approach seen in GMX on Arbitrum rather than simple inflationary farming.
On the lending side, LayerBank stands out aiming to unify borrowing like Aave did on Ethereum. This lending platform lets users use stNIBI (the liquid-staked version of NIBI) or uBTC (yield bearing BTC provided by B^2 Network) as collateral, improving composability within the Nibiru ecosystem and letting users borrow against their assets without having to sell them. This also opens the door to looping strategies and basis trading strategies.
Moreover, a marquee futures trading platform is under development called Sai, where users can place leveraged trading positions entirely on-chain. Sai would have sub-second settlement, rivaling dYdX on its own home chain.
9.2 | Liquid Staking:
Nibiru’s liquid-staking market has consolidated around Eris Protocol, making it comparable to Lido on Ethereum or Marinade on Solana. When users liquid stake their NIBI tokens, they receive stNIBI in return. Eris Protocol has more than 35M NIBI on its smart contract, allowing users to boost network security and earn staking rewards while maintaining liquidity and the ability to use their tokens in DeFi. stNIBI is composable across most Nibiru dApps.
9.3 | NFTs:
Nibiru now hosts projects that blend real-world utility and collectibles—similar to Flow’s strategy with NBA Top Shot. This consumer-focused pivot has attracted loyalty platforms alongside a fresh marketplace.
Syfu (a gamified experience with growth-oriented NFTs and token rewards) and Element (a well known marketplace with built in tools for minting, whitelisting, and community building) offers the service needed by both collectors and artists to trade and create NFTs in the Nibiru Ecosystem. Additionally, Unstoppable Domains let users buy a .nibi domain in order to personalize its address, simplifying transfers and putting their identity on the blockchain.
9.4 | Bridging & Interoperability:
Nibiru prioritizes seamless cross-chain connectivity, offering users multiple options to move assets in and out of the ecosystem. ChangeNow provides a user-friendly experience for quick asset bridging and fiat purchases without complex interfaces.
Furthermore, Nibiru offers native support for IBC (Inter-Blockchain Communication), the standard for interoperability within the Cosmos ecosystem. IBC enables transfers between Nibiru and other Cosmos chains like Osmosis or Cosmos Hub, ensuring deep integration with the interchain economy.
On the EVM side, Nibiru integrates Stargate, powered by LayerZero, one of the most liquid and secure bridges for moving stablecoins like USDT or USDC and other assets between chains.
9.5 | Wallets:
Nibiru's blockchain supports classic Cosmos wallets like Keplr, Leap and Cosmostation, as well as EVM wallets like MetaMask and Rabby, meaning users don't have to familiarize themselves with new wallets or store new seeds making it easier to onboard new people.
9.6 | Miscellany:
Nibiru’s ecosystem includes a growing range of Dapps in this cycle’s trending verticals such as prediction markets and memecoin launchpads.
BRKT offers users a betting platform where they create their own prediction markets, including binary outcomes and bracket tournament betting while PRDT keeps it more streamlined, focusing just on binary options.
Omni is introducing two product suites to the Nibiru ecosystem: Omni Swap and Omni Pump. Omni Pump enables anyone to launch a memecoin within minutes (with its own bonding curve) and create a whole community around it while Omni Swap lets users trade the bonded memecoins in a V2-style DEX.
Routescan Explorer is a Multichain explorer built by the same team powering Avalanche and Optimism Explorers which supports Nibiru EVM.
9.7 | Emerging EVM Applications:
As Nibiru continues to expand its ecosystem, several EVM-native protocols are expected to launch. Among them:
MIM Swap: A stable-focused AMM designed to minimize slippage on stablecoin trading pairs, ideal for efficient and predictable swaps.
ICHI: A yield automation platform where users can deposit stablecoins into vaults and earn yield through risk-managed strategies, all without active management.
BIMA: A BTC-backed lending protocol that allows users to deposit BTC and mint USBD, a native overcollateralized stablecoin. Once minted, USBD can be staked to earn sUSBD, which represents the user’s staked position and unlocks further yield-generating opportunities within the ecosystem.
9.8 | The State of Nibiru’s Ecosystem:
By early 2025, Nibiru is still an emerging Layer-1 in terms of user adoption and total value locked, especially when compared to established networks. Major Layer-1s like Ethereum or Solana and popular L2s like Arbitrum have far larger ecosystems with hundreds of live dApps and substantial liquidity. It’s important to acknowledge that Nibiru has not yet reached that scale. For example, Ethereum’s Layer-2 networks (Optimism, Arbitrum, Base, etc.) benefitted from instant portability of Ethereum’s DeFi and NFT apps, allowing them to amass users and TVL quickly.
In contrast, Nibiru (launching a new chain from scratch) had to bootstrap its community and liquidity largely on its own in the initial months. Some other 2023-era Layer-1s faced similar hurdles – for instance, Aptos and Sui launched with enormous hype and funding but saw mixed results in retaining developers and users after launch, and Cosmos-based chains like Sei Network or Archway started with targeted use-cases but are still growing their dApp count.
That said, Nibiru has shown a competitive pace of ecosystem growth for a young chain that has been building both EVM and WASM. Many new Layer-1s struggle to get beyond a handful of demo apps in their first year. Nibiru’s strategy of courting externally developed apps is paying off by bringing in battle-tested protocols (for example, Abracadabra’s stablecoin system) rather than relying solely on unproven local projects. This contrasts with some competitors that launched with mostly proprietary dApps which sometimes failed to gain traction. The decline of Nibiru’s earlier ecosystem projectsDropspace and Chess3 might have been seen as setbacks, but in context, those projects gave way to stronger entrants.
In terms of ecosystem maturity, Nibiru is candid about its iterative approach. The chain’s evolution demonstrates that it can adapt its roadmap to what developers and users want. This is a strength that not all platforms have. For instance, some layer-1 projects maintain rigid roadmaps or fail to pivot when initial plans don’t pan out, leading to stagnation. Nibiru’s willingness to quickly integrate EVM support and attract outside dApps is reminiscent of successful pivots by projects like NEAR (which introduced an EVM layer to draw in Solidity developers) or Polygon (which expanded from a single solution to a multi-solution ecosystem). By remaining flexible and developer-centric, Nibiru positions itself to catch up with more established ecosystems. While it still has a way to go in absolute metrics (users, TVL, transactions), the diversity of its current dApp lineup and the steady cadence of new launches suggest that Nibiru’s ecosystem is building momentum.
10 | Final Thoughts
Nibiru Lagrange Point is not only a technical upgrade that improves upon traditional blockchains design by integrating a scalable, novel modified BFT consensus, adaptive execution, and Multi VM support. It's a whole ecosystem upgrade that brings significant benefits to developers, end users, and validators.
10.1 | For Developers
Nibiru upgrades are designed to make building on the platform more efficient, flexible, and developer-friendly.
Developers can choose the VM that best suits their project without being locked into a single environment. Multi VM support allows developers to use familiar Ethereum tools for EVM-based contracts or use Rust-based Wasm contracts for security features. Cross-VM interoperability makes possible innovative applications, enabling new types of Dapps.
This reduces the learning curve for developers coming from Ethereum or other ecosystems while fostering composability across VMs. Plans for future VM support further ensure Nibiru remains a versatile platform as new technologies emerge.
Importantly, the ability for developers to utilize their VM of choice positions Nibiru, a smaller blockchain, well to integrate existing projects into the ecosystem. Smart contracts that have been previously audited may be deployed seamlessly, without the costs associated with translating smart contract code.
10.2 | For End Users
Traders, NFT collectors, Dapp users, all of them benefit from Nibiru Lagrange Point.
Thanks to Validator Clustering, QUIC, and Adaptive Execution, users can execute transactions quickly and affordably, even during periods of high network activity. This is especially useful for Dapps that require fast throughput and low fees, such as in perpetuals trading (especially with high-frequency activities) or during times of high activity (you don't want to be left out of that hyped TGE because you don't have enough tokens for fee).
Multi-lane mempool and blocks ensure that time-sensitive transactions are prioritized over less urgent ones, first executing critical primitives like oracle updates and liquidations, while also containing potentially negative effects from MEV behavior and black swan events.
Additionally, with Multi VM support, developers can build more sophisticated and cross-ecosystem products that draw from Wasm and EVM Dapps, unlocking more complex applications, better capital efficiency, and new use cases. This not only positions Nibiru as a good place to build, but also makes it an attractive place to create innovative Dapps, such as multi-ecosystem aggregators that optimize swap execution not just across different applications, but across entire ecosystems, leading to less slippage.
10.3 | For Validators
Nibiru Lagrange Point upgrade makes the Validator role more efficient, inclusive, and scalable.
NibiruBFT reduces communication complexity, lowering the messaging and computational overhead for consensus. Additionally, blocks are processed more efficiently, with fewer re-executions or rollbacks. A more efficient consensus protocol not only facilitates inclusivity and decentralization, but also results in greater validation upside for validators. On the other hand QUIC’s stream multiplexing, and connection migration capabilities improve validator communication, mitigating issues like packet loss or IP changes. As a result, Nibiru’s validators will be able to leverage QUIC’s advanced architecture to meet uptime requirements and avoid slashing conditions
By addressing the needs of these key stakeholders, Nibiru creates a balanced ecosystem that fosters innovation, accessibility, and trust, positioning it as a compelling platform for the future of Web3. All these features can lead to more activity on the network as it continues to mature and differentiate itself from other competing Layer-1 networks.
Multi-VM chains open powerful new design space and novel risk. Explore how our L1/L2 Protocol Audit service secures consensus, execution, and state transitions across complex blockchain architectures.
10.4 | Bottom-Line
Short-term, Nibiru competes for the “performance-plus-EVM” niche now targeted by Sei v2 and soon Monad/MegaETH. Winning credible throughput benchmarks in 2025 is critical.
Medium-term, if Lagrange Point proves that clustered BFT and adaptive execution scales without validator centralization, the obvious next step is onboarding a marquee perps DEX or RWA protocol that showcases the priority-lane advantage.
Long-term, success hinges on liquidity gravity. Cross-VM composability is compelling, but bridging incentives and UX (e.g., intent-based routers) must compete with the likes of Base’s user onboarding appeal through Coinbase or Solana’s ease of recognition.
Nibiru is a calculated bet on “single-state convergence”: merging EVM mind-share with Solana-like parallelism and Aptos-grade latency. The architecture is elegant and addresses known pain-points (oracle lag, VM silos). Execution risk is non-trivial, but if upcoming benchmarks validate the design, Nibiru could earn a seat next to Aptos, Sui, and Solana in the performance-maxi cohort while retaining Ethereum developer familiarity.